Understanding the Maintainability of Your Code Base
The maintainability of your code base plays an important role for the future-proofness of your system. Getting an overview and being able to assess it correctly are important preconditions for steering development and maintenance activities in a meaningful way.
How (Not) to Measure and Assess Maintainability
Maintainability cannot be expressed in terms of a single number, while still retaining valuable and actionable insights [1]. Rather, we suggest to determine maintainability by investigating and assessing different quality criteria, such as how the code is structured or how much redundancy is present in the code base. Differentiating between such quality criteria allows you to get a more thorough, actionable, and objective understanding of the underlying problems and to develop an appropriate and targeted improvement strategy.
In general, many quality metrics can be calculated on the level of individual files or classes and turned into a weighted average. Often, however, this raw average value is of little use: Are all the problems in a single file or is the problem rather equally distributed? What should be done concretely to improve the situation? We recommend to always examine the distribution of a metric over the entire system. In Teamscale, you can easily get such an overview with assessment charts or treemaps.
Prerequisite: Determine the Correct Scope
To obtain meaningful results, it is important to set the right measurement scope, especially in a grown code base. In addition to the actual system code, whose maintainability you usually want to assess, a typical code base often contains other source code files, such as code written by a third party or generated code. Since you do not manually maintain those files, you don't need to assess their maintainability. The system code itself typically comprises application code and test code, which you might want to evaluate differently. For instance, how well exception handling is done might be of less importance in test code than it is in application code. Further, there might be "legacy" areas in the code base that are outside of the focus of current development efforts.
In order to measure and assess the maintainability of the relevant areas of your code base, you have to make sure the analysis scope is set accordingly. This includes both setting up your project in a meaningful way for correct measurement, e.g. excluding generated code, as well as looking at the right portion of the code base, e.g. the application code or a specific folder, when examining and assessing the results.
Measurement vs. Assessment
It is important to notice that there is a difference between measurement and assessment:
- Measurement denotes collecting quantitative information about certain properties of a study object.
- Assessment refers to the evaluation of the measurement results. Assessment requires an interpretation of the measured information.
Tools like Teamscale measure different aspects of maintainability, such as the length of the methods in the code base. Comparing the measured results with coding standards and commonly accepted best practices allow us to deliver a first interpretation. However, a thorough assessment typically requires a lot of contextual knowledge, such as about the history of the system, the development and maintenance process, the system's goal, its criticality, its architecture, field problems and so on. This is why assessments should be carefully crafted by experts based on the obtained measurement results.
What Makes Maintainable Code?
A single maintainability problem, such as a single long method or a copied file, does not present a serious issue for a system. But without effective counter measures, the quality of any system will gradually decay. Especially grown code bases often already contain a large number of quality problems. Chances are you already find yourself far from an "ideal" target.
As continuous progress is the key to successfully improving software quality, it is especially important to observe the trends of relevant quality criteria. However, you also need to be able to understand how far you are off regarding the different indicators to be able to assess the overall situation.
The quality criteria we apply in practice [2] generally estimate, how frequently developers are faced with code that contains specific maintainability problems in their daily work, or—as one customer coined it—the quality of life of the developers. To this end, we measure how prevalent a specific problem is in the code base and apply a threshold for its evaluation.
The following sections explain some of the most important quality criteria for maintainability.
Code Structure
With "Code structure" we refer to different aspects of how code is organized. Insufficient structure complicates the orientation in the code base and hinders identifying relevant locations when having to modify the code. Moreover, how well the code is structured affects the impact of a change and potentially further required modifications.
In the following we describe three important quality criteria that assess code structure in more detail: File Size, Method Length and Nesting Depth. They capture how well code is distributed across files, within a file, and within a method.
In each case, thresholds are used to classify the code into different classes corresponding to good structure (Green), improvable structure (Yellow), and poor structure (Red) as shown on the following illustration.

Note
The illustration shows typical thresholds for higher level languages such as Java, C#, or C++. Depending on the language in your code base and your coding guidelines, you might use different thresholds. Teamscale comes with pre-configured thresholds for all supported languages, but you can modify these to fit your needs.
In practice, it is very difficult to completely avoid code with improvable or poor structure, especially in grown code bases. There will always be some structural problems, such as a long method to create UI objects or an algorithm with some deep nesting. But these problems are not a threat to maintainability unless they take the upper hand.
For this reason, rather than judging single problems, we assess how much of the code is affected by structural problems:
Code Structure: Target Best Practice
Ideally, no more than 5% of the code should be classified as red, and no more than 25% of the code should be classified as red or yellow for each of the code structure quality criteria [2]. In other words, in a healthy code base, at least three quarters of the code should be well structured and at most 5% may be structured poorly, as illustrated with the following distribution charts:

In the following we elaborate on the three quality criteria for code structure and explain why they are meaningful indicators.
File Size
When looking for the location to perform a code change, the first step is normally to find the right file. The larger this file is, the more effort is required on average for the further search within the file. Overly long files hamper program comprehension and have a negative influence on maintenance.
Teamscale measures the length of source files in lines of code (LOC) or source lines of code (SLOC), i.e. lines of code without whitespace and comments.
Method Length
Many programming guidelines recommend to limit the length of a method to a single screen page (typically 20 to 50 lines) [3]. The reason behind this rule of thumb is that, in order to modify a method, a developer normally has to read and understand the entire method. This is easier if the entire method or at least most of it is visible at the same time on the screen without scrolling. Additionally, long methods require developers to comprehend long statement sequences even if only simple changes are performed. Therefore, long methods make code overall harder to comprehend [4].
Further, long methods often lead to reuse of code fragments through copy-and-paste, thus causing multiple additional problems. Beyond that, long methods are also harder to test, which is why it is not surprising that long methods are more error-prone than short methods [5].
Nesting Depth
Most programming languages provide block or nesting mechanisms that allow to control the scope of certain statements. Blocks are used in the bodies of methods and classes, but also in control flow operations such as conditional execution (e.g. if) or loop statements (e.g. for, while).
The level of nesting affects code understanding, as each nesting level extends the context required to understand the contained code. Therefore, code with little nesting is easier to understand than code with deep nesting [3]. The general assumption is that two nesting levels of control structures can still be understood with reasonable effort by developers (where counting starts at the method level), while starting with nesting level three, this requires disproportionately more effort.
Furthermore, deep nesting also makes testing a method more complex as more different branches of the control flow have to be covered.
Redundancy
Most programming languages provide abstraction mechanisms that allow developers to reuse existing functionality. Nevertheless, copy-and-paste (and possibly modify) is widely utilized to reuse existing code. In practice, this approach often leads to a multitude of source code duplicates—so called "clones"— which are typically very similar on a syntactic level and hamper the maintenance and evolution of a system in various ways.
Why Redundancy Impedes Maintainability
Clones unnecessarily increase the amount of code and hence raise the efforts needed for program comprehension and quality assurance activities [6, 7]. Any changes, including bug fixes, that affect a clone usually have to be propagated to all of its copies. Localizing and modifying these copies creates significant overhead.
Besides higher efforts for maintenance and testing, duplicated code is also more error-prone, because copies that are out of sight are easily missed when changing code that has been cloned. Often, developers do not even know that a piece of code has been copied elsewhere. In practice, this can lead to inconsistencies resulting in non-uniform behavior or errors [8].
To learn how Teamscale can support you in preventing these inconsistent changes, please refer to our blog post.
How we Measure Redundancy
Teamscale uses clone detection to analyze the redundancy in your system and find duplicated code. To get significant results, by default only clones with at least 10 common consecutive statements are flagged.

To quantify the overall extent of redundancy, Teamscale calculates the metric clone coverage, which measures the fraction of statements in a system that is part of at least one copy. Hence, clone coverage can be interpreted as the probability that a randomly selected statement in your code base has at least one copy.
Similar to structural problems, it is very difficult to completely avoid redundancy, especially in grown code bases. Therefore, rather than assessing single clones, we assess how much of the code is affected by duplication:
Redundancy: Target Best Practice
Ideally, the clone coverage of your code base should not exceed 5% [2]. Based on our experience, if clone coverage is between 5% and 15%, developers are regularly confronted with clones. As a rule of thumb, a clone coverage value of over 15% indicates that developers have to deal with redundancy on a daily basis.
Other Relevant Criteria
Code structure and redundancy are two very important quality criteria for assessing the maintainability of your code base. However, for a comprehensive examination of maintainability we recommend to look into the following criteria as well.
Commenting
In addition to the actual program statements, source code typically also contains comments. Their purpose is to document the system and help fellow developers to understand the code and the rationale behind a specific solution. High quality comments are widely considered to be crucial for program comprehension and thus for the maintainability of a system [9]. Nonetheless, in practice, code is often undocumented due to time pressure during development.
Consequently, two criteria for code comments should be investigated: Comment Completeness, i.e. are the relevant portions of the code documented, and Comment Quality, i.e. are the existing comments concise, coherent, consistent, and useful? Teamscale provides checks for both criteria.
Naming
About 70% of source code in software systems consist of identifiers [10]. Identifiers provide names for important source code entities, such as classes, enums, interfaces, methods, attributes, parameters, and local variables. Consequently, meaningful, correct identifiers are crucial for reading and understanding your source code [10].
When investigating identifier names, two aspects should be examined:
- Are the Naming Conventions from your coding guidelines being followed consistently throughout the system?
- Is the Naming Quality acceptable, i.e. are identifiers easy to read, expressive, and suitable for the domain?
Teamscale can check naming conventions pretty extensively, while assessing the quality of identifier names usually requires manual inspection.
Code Anomalies
The term code anomalies broadly refers to violations of commonly accepted best practices. In many cases, such best practices are programming language specific—consider for instance PEP-8 for Python. Nevertheless, they often cover similar best practices regarding maintainability, such as commented out code, unused code, task tags, missing braces, empty blocks, usage of goto, formatting and so on.
The following Teamscale screenshot shows an unused variable finding, one of the typical code anomalies often found in Java code:

When investigating the maintainability of your code base, make sure to examine the number of code anomalies per thousand lines of code, i.e. the Findings Density. This gives you a measure for how often developers are confronted and hindered by code anomalies. Choose an appropriate threshold based on the number of best practices you are checking.
In Teamscale, you can use a Quality Indicator when configuring the analysis profile to specify which findings should be counted as code anomalies. Make sure to enable calculating Findings Density, when configuring the Quality Indicator.
Exception Handling
Many programming languages provide exception handling to deal with deviations from the normal program execution. Possible deviations range from programming mistakes, (e.g. dereferencing a NULL pointer), over limitations of the execution environment, which in turn can hint at a programming mistake (e.g. stack overflow, running out of heap memory), to environment limitations out of the program’s control (e.g. write errors due to full disc, timed-out network connections). In addition, exceptions are often used to indicate an erroneous result of a function call, such as parsing errors or invalid user input.
Improper exception handling can harm the maintainability of your code base in several ways. Consequently, when investigating the maintainability of your code base, you should also analyze if exceptions are handled adequately. Make sure to at least check the following handful of guidelines:
- If generic exceptions are thrown generously, it gets difficult to handle deviations selectively, which often leads to more complicated control flow. As a rule of thumb, only the most specific exception possible should be thrown and caught.
- It is good practice to introduce specific custom exceptions for your system, if this is doable in your programming language. Custom exceptions represent specific problems and allow to handle domain specific deviations from the normal execution selectively. If possible, custom exceptions should be grouped into a suitable exception hierarchy.
- Empty catch blocks should be avoided at all costs. Ignored exceptions do not influence the control flow, are not presented to the user, and—most importantly— are not logged. As a consequence, empty catch blocks might actually hide erroneous states.
- Losing stack traces vastly complicates finding problems. Hence, the stack trace should always be kept, even when throwing other exceptions. Simply printing the stack trace is usually not enough. At the very least, the stack trace should be logged with the system's logging mechanism. When throwing from a catch block, the original exception should be wrapped, if possible.
- Instead of catching
NULLpointer exceptions, developers should check whether a specific object isNULL.
Teamscale provides checks to analyze exception handling for several programming languages, including Java. The following screenshot shows a finding for a lost stack trace:

Maintainability Overview in Teamscale
The quality criteria described above play a central role in Teamscale. You can access them in various places to get an overview of the maintainability of your code base:
- The Dashboard perspective allows you to configure widgets that visualize any of the above-mentioned criteria, including assessment charts and treemaps. You can configure thresholds for the different metrics and observe trends over time.
- The Metrics perspective shows an overview of all metrics configured for your project, including the maintainability metrics described above:
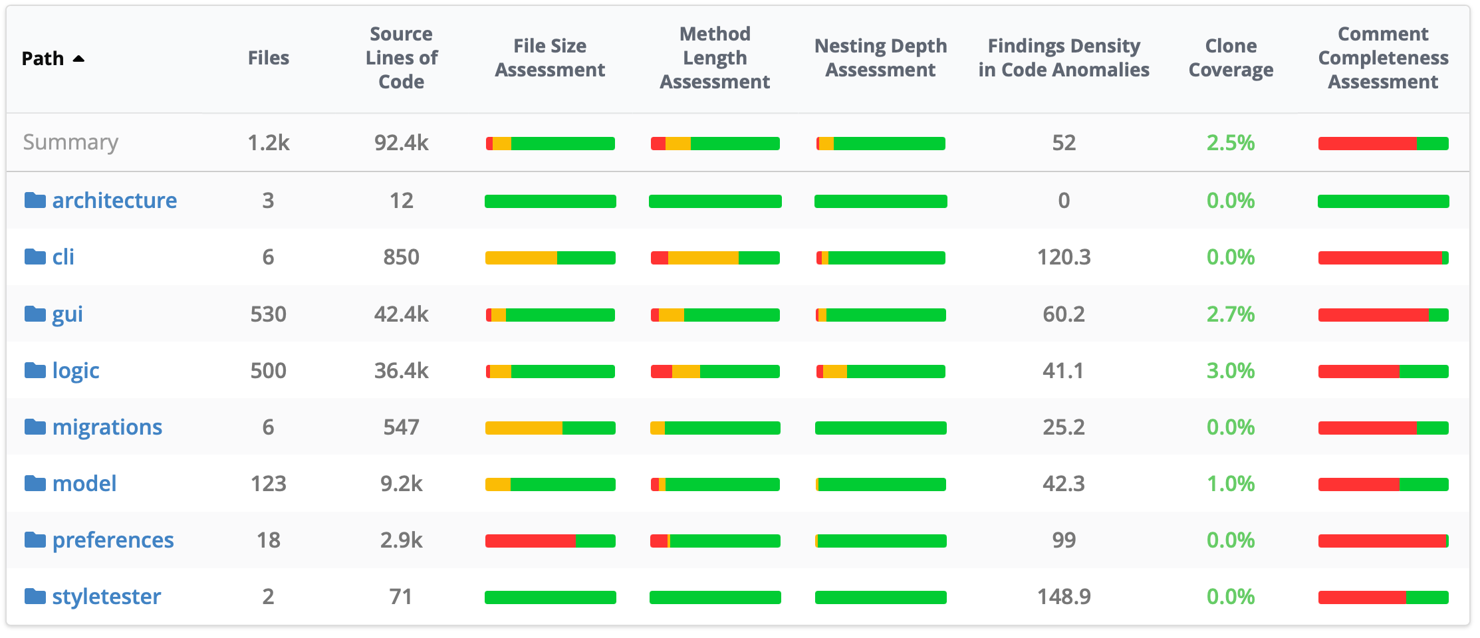 It allows you to drill down into each metric for every folder in your code base. It also provides a quick way to view a treemap visualizing the distribution of the metric across the files in the code base as well as the history how the metric developed over time.
It allows you to drill down into each metric for every folder in your code base. It also provides a quick way to view a treemap visualizing the distribution of the metric across the files in the code base as well as the history how the metric developed over time.
Further Reading:
- Demystifying Maintainability
M. Broy, F. Deissenboeck, M. Pizka, In: Proceedings of the Workshop on Software Quality (WOSQ’06), 2006 - Continuous Software Quality Control in Practice
D. Steidl, F. Deissenboeck, M. Poehlmann, R. Heinke, and B. Uhink-Mergenthaler, In: Proceedings of the IEEE International Conference on Software Maintenance and Evolution (ICSME). 2014 - Clean Code: A Handbook of Agile Software Craftsmanship
R. C. Martin, In: Robert C. Martin Series. Prentice Hall, Upper Saddle River, NJ, Aug. 2008 - Measuring program comprehension: A large-scale field study with professionals
X. Xia, L. Bao, D. Lo, Z. Xing, A. E. Hassan, S. Li, In: IEEE Transactions on Software Engineering (TSE). 2017 - Mining Metrics to Predict Component Failures
N. Nagappan, T. Ball, A. Zeller, In: Proceedings of the 28th International Conference on Software Engineering (ICSE). 2006 - Survey of research on software clones
R. Koschke, In: Proceedings of the Dagstuhl Seminar on Duplication, Redundancy, and Similarity in Software. 2007 - A survey on software clone detection research
C. K. Roy, J. R. Cordy, In: Technical report, Queen’s University, Canada. 2007 - Do code clones matter?
E. Juergens, F. Deissenboeck, B. Hummel, S. Wagner, In: Proceedings of the 31st International Conference on Software Engineering (ICSE). 2009 - Quality Analysis of Source Code Comments
D. Steidl, B. Hummel, E. Juergens, In: Proceedings of the 21st IEEE Internation Conference on Program Comprehension (ICPC’13). 2013 - Concise and Consistent Naming
F. Deissenboeck, M. Pizka, In: Proceedings of the International Workshop on Program Comprehension (IWPC’05). 2005