Repository Connector Options Reference (SVN, Git, Azure DevOps, etc.)
To create a project, Teamscale needs to be connected to your version control system. To this end, it offers several different repository connectors. We describe the options for each repository connector.
Shared Connector Options
Setting up the other connectors to source code repositories and issue trackers is very similar to the Git connector setup. Many connectors share general options such as a polling interval and therefore, we only describe the options (if there are any) for first connector that uses it. If there are no additional options in a connector, we don't document the connector separately.
Common and Git-specific Connector Options
| Default branch name | The name of the branch to import. |
| Account | Account credentials that Teamscale will use to access the repository. Clicking on the button opens a credentials creation dialog.
|
| Path suffix | Should Teamscale only analyze a subdirectory of the repository? |
| Connector Identifier | Teamscale will use this identifier to distinguish different connectors in the same project. (Teamscale-internal only) |
| Included file names | One or more Ant Patterns separated by comma or newline to restrict the analysis on a subset of files. A file is included in the analysis if any of the supplied patterns match. Typical examples:
|
| Excluded file names | One or more Ant Patterns separated by comma or newline to exclude from the analysis. A file will be excluded if any of the exclude patterns match. Typical examples:
|
| Important Branches | Important branches are preferred in addition to the default branch when assigning commits to branches. List of regular expressions with decreasing priority. Examples: develop, release/ |
| Include submodules | Whether to also analyze code in submodules. |
| Submodule recursion depth | The maximum depths of nested submodules that will be analyzed. (Has no effect if Include submodules is not selected.) |
| SSH Private Key ID | The ID of an SSH private key stored in Teamscale which will be used when connecting to a Git Account over SSH. You can manage all your Git private keys on the Settings page of the Admin perspective, in the Git section. When using a Git private key, the Account used by the connector has to be configured as follows: The URL has to contain the user name (e.g., ssh://username@gitserver/path/to/repo.git), the password and the username may be left empty. |
| Enable branch analysis | This checkbox activates our branch support feature. If you select it, Teamscale will analyze all branches of the repository. If branch analysis is enabled, the Default branch name option specifies the main branch (usually main or master) |
| Included branches | Explicitly control which branches will be analyzed. (hidden if Enable branch analysis is not selected.) |
| Excluded branches | Explicitly state which branches to exclude. Note that Teamscale will create so called anonymous branches for all historic branches whose name could not be reconstructed. By default these are filtered using the exclude pattern _anon.* |
| Start revision | The first revision that will be analyzed. You can enter a date (which selects the first revision after the date) or a revision hash. |
| End revision (expert option) | The last revision that will be analyzed. If the default value is selected, the history up to the latest revision is read. |
| Content exclude | A comma-separated list of regular expressions. Teamscale will exclude all files that match one of these filters. |
| Polling interval | How often should we query the repository and update our findings? (Unit is seconds) |
| Include files stored via Git LFS | Teamscale can be configured to manage files stored via Git Large File Storage (LFS).
|
| Test-code pattern type (expert option) | Controls how test-code path patterns are interpreted. They are either specified as Ant-style patterns with wildcards (*, **, ?) and case-insensitive matching, or specified as regular expressions. Defaults to Ant patterns. |
| Test-code path pattern (expert option) | Patterns describing the file paths to be considered test code. The pattern type is controlled by Test-code pattern type. Files that match one of the given patterns are considered to be test code unless also matched by a pattern in Test-code path exclude pattern. Patterns can be separated by comma or newline.Files matched as test code will be excluded from test gap treemaps. In addition, these files will not have a line coverage metric calculated and are not considered for the "Test Coverage" feature in the Merge Request details view, if the option 'Exclude Test Code' under the Test Coverage group is enabled in the corresponding analysis profile. |
| Test-code path exclude pattern (expert option) | Patterns describing the file paths that should be excluded from the test-code files matched by option Test-code path pattern. The pattern type is controlled by Test-code pattern type. Files that match one of the given patterns will not be considered test code. Patterns can be separated by comma or newline. |
| Branch transformation (expert option) | Defines regular expression rules to virtually rename branches during analysis. Rules are specified as 'pattern -> replacement' pairs and applied in the order in which they are defined. Execution Flow
Transformation target names (e.g., 'main') are automatically excluded from the initial branch list to prevent duplicate analysis. Regex Behavior Examples
|
| Prepend Connector Identifier (expert option) | Whether to include the connector identifier as a prefix for the created file paths. |
| Text filter (expert option) | One or more regular expressions separated by comma describing what parts of a file should be excluded from analysis (e.g. generated code). |
| Language mapping (expert option) | Mapping from Ant Patterns to language used to override default language mapping. Typical examples:
|
| Analysis report mapping (expert option) | Mapping from Ant Patterns to report format to be imported. Typical examples:
|
| Partition Pattern (expert option) | A regular expression to extract the partition from the path of the artifacts. The first non-null group is used as partition. Example: coverage/([^/]+)/ to use sub-folders of coverage as partition |
| File-size exclude (expert option) | A file size limit (i.e., contents of larger files are shown in grey and not analyzed) given in bytes with units (e.g. B, KB, KiB). Defaults to 1MB which corresponds to about 20-30 kLOC. |
| Source library connector (expert option) | Determines if the contained files should only be used for source library lookup, but not for analysis. For example, this can be used for third-party C/C++ header files that are required for compilation. |
| Run to exhaustion (expert option) | Determines if the repository should not be polled after the current head is reached. |
| Preserve empty commits (expert option) | Determines if Teamscale should also read and process commits without relevant changes. This can be useful for showing these in the activity stream as well or for post-processing empty commits (e.g. for Gerrit voting). Disabling this can improve performance. Please note that all fork commits will be preserved in any case, even if they are empty and this option is not set. |
| Delta size (expert option) | Adjusts the size of deltas produced by this connector. |
| Path prefix transformation (expert option) | Prefix transformations that are applied to the paths from the repository. Examples:
|
| Path transformation (expert option) | Regex transformations that are applied to the paths from the repository. Example: /trunk/ -> / |
| Encoding (expert option) | Sets the encoding to be used when reading files (e.g. UTF-8, latin1). |
| Author transformation (expert option) | Regex transformations that are applied to the authors of the repository. Example: Bob -> Robert |
| Fetch additional ref specs (expert option) | Option for fetching additional ref specs. Allows users to specify additional ref specs to fetch, as well as an extraction pattern to display them in the UI. The additional refs can be picked as git tags in the time picker UI. Example: refs/builds/tags/*:refs/remotes/origin/builds/tags/* -> refs/remotes/origin/builds/tags/./.\.(.*) |
| Skip Voting on merge requests without relevant changes (expert option) | Whether Teamscale should vote on merge requests that do not contain any relevant changes. If set, also results in Teamscale not producing any findings badge in the merge request. |
Team Foundation Server (TFS)-specific Connector Options
| Path suffix | A common subdirectory on the Azure DevOps Server appended to the account URI. Leave empty if the whole directory structure is relevant. This is the root directory when looking for branches if branching is enabled. |
| Branch path suffix | The sub path (relative to the branches) that should be analyzed. Leave empty to analyze all code within each branch. |
| Branch lookup paths | The paths in the repository separated by commas where Teamscale will search for branches within the root directory defined by the Path suffix and account URI. If set, Teamscale only looks for branches on the top level of each branch lookup path. If empty only the root directory is searched for branches on the top level. |
| Included/Excluded branches | Included and excluded branches must contain the full path to the branch relative to the root directory. This means the Branch lookup paths appended with the contained branch |
| Non-branched mode | Activates the non-branched mode for TFS. If it is enabled, Teamscale ignores the default branch and treats everything found in the root directory of the repository as content to analyse. If the option is disabled, Teamscale interprets the directories found at the Branch lookup paths as branches. It is not possible to enable both the branch analysis and the non-branched mode. |
Subversion (SVN)-specific Connector Options
| Enable Externals | Whether to also parse and interpret svn:externals properties. |
| Externals Includes/Excludes (expert option) | Comma separated list of Ant Patterns describing the directories that are (not) checked for svn:externals. Use . to denote the top-level directory. |
| Branches directory | A path in which to look for branches. Defaults to branches. |
| Ignored Revisions (expert option) | List of revisions to be ignored when crawling the SVN repository. This can be used to exclude revisions that describe erroneous SVN operations, such as invalid branch creations, that later have been corrected. Note that misuse of this option can lead to unexpected analysis behavior. |
File System-specific Connector Options
| Input directory | The path of the source-code directory |
Vote-Supporting Connector Options
Teamscale can cast merge request votes on platforms that support it. The connectors that implement this behavior are:
- Azure DevOps Git
- Bitbucket Cloud
- Bitbucket Data Center
- Gerrit
- Gitea
- GitHub
- GitLab
- SCM-Manager
The common options for these connectors are:
| Enable Findings Integration | Prerequisite for all findings related merge request actions. Opens up options like Findings badges. This option does nothing on its own. |
| Enable Findings Badge | Includes Teamscale findings badge in voting. This badge is usually added to the merge request's description and shows the findings churn of the merge request, i.e. findings that were added, removed or are in changed code of this merge request. |
| Enable Detailed Line Comments For Findings | When enabled, a Teamscale vote will carry a detailed comment for each generated finding that is annotated to the relevant line in the reviewed file. |
| Aggregate Findings in Single Comment | When enabled, Teamscale will aggregate all related findings in a commit into a single comment before annotating it to the reviewed file. The aggregated findings could be multiple identical findings or different findings sharing the same type (e.g. structure findings). This aims to reduce redundancy and not to overcrowd the merge request with repetitive comments. Example: if a commit introduced 20 "Interface comment missing" findings, instead of adding 20 individual comments to the merge request, Teamscale will only add a single comment "This file contains 20 instances of: Interface comment missing". |
| Detailed Line Comments Limit for Findings | Maximum allowed number of detailed line comments when annotating merge requests, in case the "Enable Detailed Line Comments For Findings" option is enabled. If the number of added findings exceeds the limit, no line comments will be added to the merge request and a warning message is displayed. Please note that some platforms enforce limits in their API. |
| Enable Voting for Findings | Whether Teamscale should vote on merge requests. The vote reflects whether new findings are introduced in the merge request. Depending on the platform and more specifically the repositories' configuration, this can block the merging of a merge request. |
| Enable Commit Alerts for Merge Requests | When enabled, a Teamscale vote will carry a detailed comment for each commit alert that is annotated to the relevant file. |
| Enable Testing Integration for Merge Requests | Prerequisite for all test related merge request actions. Opens up options like Test Gap integration or voting for Test Coverage. This option does nothing on its own. |
| Enable Test Gap Integration for Merge Requests | Prerequisite for all test gap related merge request actions. Opens up options like Test Gap badges and Test Gap line comments. This option does nothing on its own. |
| Enable Test Gap Badges | Includes Teamscale test gap badge in voting. This badge is usually added to the merge requests description. |
| Add Detailed Line Comments for Test Gaps | When enabled, a Teamscale vote will add a detailed comment for each untested method or function. Comments are annotated to the relevant methods or functions in the reviewed files in the merge request diff view. Test Gap comments will be added, provided that the following conditions are fulfilled:
|
| Limit for Test Gap Comments | Maximum allowed number of test gap comments when annotating merge requests, in case the "Add Detailed Line Comments for Test Gaps" option or the "Add Test Gaps Summary in a Single Comment" option is enabled.
|
| Add Test Gaps Summary in a Single Comment | When enabled, a Teamscale vote will add a single merge request comment with a summary of all the untested methods or functions in the merge request. The Test Gap summary comment will be added, provided that the following conditions are fulfilled:
|
| Line coverage threshold | The required line coverage for added and changed lines (in percent, 0-100). Merge requests with a lower changed line coverage will receive a negative vote. |
| Merge request polling interval | Delay used for polling the merge requests in seconds. |
| Ignore Yellow Findings For Votes (expert option) | When enabled, only red findings will cause Teamscale to cast a negative vote on merge requests. Note that this option has a different behavior for the Gerrit connector. |
| Ignore Yellow Findings For Comments (expert option) | When enabled, Teamscale will only add comments for red findings to the merge request. |
| Partitions required for Voting (expert option) | Comma separated list of external upload partitions that are expected to be present after a code commit to actually vote. This is used to prevent voting too early when further external uploads (e.g., test coverage reports) are expected. |
| Vote Include/Exclude Patterns (expert option) | The include/exclude-filename patterns filter findings from both the findings badge (if the badge is enabled) and the inline comments (if they are enabled). Teamscale will still add a findings badge, even if none of the changed files of a merge request match the filter. |
| Badges for Critical Changes (expert option) | Badges added to merge requests indicating that modifications in predefined critical code areas occurred. Detailed instructions on configuring the critical change badges can be found here. |
Bitbucket Data Center
The Bitbucket Data Center connector can access Git repositories of Bitbucket Data Center instances and can additionally vote on pull requests.
TIP
For a visualization of how Teamscale votes in Bitbucket Data Center, see our how-to guide.
Bitbucket Data Center Options
| Enable Voting for Findings | Whether Teamscale should vote on pull requests based on the presence of new findings. The vote is added as a build status and can potentially block the merging of pull requests, depending on the repository's configuration. |
| Enable Voting for Test Gaps | Whether Teamscale should vote on pull requests based on the presence of test gaps. The vote is added as a build status and can potentially block the merging of pull requests, depending on the repository's configuration. |
| Ignore yellow Test Gaps for voting | When enabled, test gaps in changed methods ("yellow" test gaps) are ignored when voting based on the presence of test gaps. |
| Enable Voting for Test Coverage | Whether Teamscale should vote on pull requests based on the test coverage percentage. The vote considers the coverage threshold specified by the option "Line coverage threshold" and whether it was reached or not. The vote is added as a check and can potentially block the merging of pull requests, depending on the repository's configuration. |
| Included build jobs | Regular expressions describing the merge request build jobs to wait for before voting with test data. Build jobs will be matched case-sensitively. |
| Excluded build jobs | Regular expressions describing the merge request build jobs to be excluded and not considered when voting with test gap data. Build jobs will be matched case-sensitively. |
| Add Detailed Line Comments For Findings and Test Gaps as Pull Request Comments | When enabled, Teamscale will add inline comments for findings and test gaps as actual comments on the pull request. |
| Add Detailed Line Comments For Findings and Test Gaps as Code Insights Report | When enabled, Teamscale will use the Bitbucket Code Insights reports to add comments for findings and test gaps. |
| Build polling interval | Delay used for polling the merge requests' build jobs in seconds. |
| Enable pull request review (expert option) | Votes by submitting a pull request review in addition to the build status. Combines the results of all enabled votes (Findings, Test Gaps, Test Coverage). |
| Add badges in a pull request comment (expert option) | When enabled, Teamscale will add all enabled badges (e.g. Findings Badge, Test Gap Badge, etc.) in a pull request comment, instead of adding the badges in the pull request description. |
| Badges for Metrics (expert option) | Metrics which should be tracked in merge requests via badges. |
| Badges for Metric Groups (expert option) | Metrics which should be included in summary badges for metric groups. These badges show the aggregated results of all the selected metrics in a group, e.g. the number of improved or deteriorated metrics in this group. |
Gerrit
The Gerrit connector can access Gerrit-managed Git repositories, and can additionally vote on changes.
Gerrit Connector Options
| Project Name | The name of the Gerrit project to connect with. |
| Ignore Yellow Findings For Votes (expert option) | When this option is enabled, the voting will be performed according to the following rules:
|
| Read Timeout (expert option) | The timeout (in seconds) used for reading data from Gerrit. |
| Authentication Mode (expert option) | The mode to use for authentication. Choose basic fallback mode if regular basic mode does not work. Possible authentication modes:
|
| Review Label (expert option) | The review label used to upload feedback to Gerrit. Defaults to Code-Review |
| Minimum Change Creation Date (expert option) | If this is set, the first analysis run will only consider open changes created after the given date. Changes that have been closed before the time of the first analysis run will be discarded completely. |
| Fetch Merged Changes (expert option) | If this is set, merged changes are also fetched. |
GitHub
The GitHub connector can access Git repositories of GitHub instances and can additionally vote on pull requests.
TIP
For a visualization of how Teamscale votes in GitHub, see our how-to guide.
GitHub Options
| Enable Voting for Test Gaps | Whether Teamscale should vote on pull requests based on the presence of test gaps. The vote is added as a check and can potentially block the merging of pull requests, depending on the repository's configuration. |
| Ignore yellow Test Gaps for voting | When enabled, test gaps in changed methods ("yellow" test gaps) are ignored when voting based on the presence of test gaps. |
| Enable Voting for Test Coverage | Whether Teamscale should vote on pull requests based on the test coverage percentage. The vote considers the coverage threshold specified by the option "Line coverage threshold" and whether it was reached or not. The vote is added as a check and can potentially block the merging of pull requests, depending on the repository's configuration. |
| Included build jobs | Regular expressions describing the merge request build jobs to wait for before voting with test gap data. Build jobs will be matched case-sensitively. |
| Excluded build jobs | Regular expressions describing the merge request build jobs to be excluded and not considered when voting with test data. Build jobs will be matched case-sensitively. |
| Build polling interval | Delay used for polling the merge requests' build jobs in seconds. |
| GitHub Server URL | The URL the GitHub instance is reachable at. |
| Context identifier (expert option) | The context identifier used for uploading the status to GitHub. Defaults to teamscale, but can be changed if multiple projects should vote for the same GitHub repository. |
| Disable automatic webhook creation (expert option) | If this is set to true, Teamscale will not create the required webhooks. Instead, you are responsible to set up webhooks according to the documentation to allow proper voting. |
| Ignore webhooks from configured user (expert option) | If this is set to true, Teamscale will ignore any webhooks triggered by the user configured in this connector, in order to avoid useless round-trips to the server. For production setups, this should be enabled and used with a dedicated build user. |
| Findings badge position (expert option) | The position of where to display the findings badge in the pull request. |
| Badges for Metrics (expert option) | Metrics which should be tracked in merge requests via badges. |
| Badges for Metric Groups (expert option) | Metrics which should be included in summary badges for metric groups. These badges show the aggregated results of all the selected metrics in a group, e.g. the number of improved or deteriorated metrics in this group. |
GitLab
The GitLab connector can access Git repositories of GitLab instances and can additionally annotate merge requests.
TIP
For a visualization of how Teamscale votes in GitLab, see our how-to guide.
GitLab Options
| Included build jobs | Regular expressions describing the merge request build jobs to wait for before voting with test gap data. Build jobs will be matched case-sensitively. |
| Excluded build jobs | Regular expressions describing the merge request build jobs to be excluded and not considered when voting with test gap data. Build jobs will be matched case-sensitively. |
| Build polling interval | Delay used for polling the merge requests' build jobs in seconds. |
Subversion (SVN) Branch Analysis
Subversion by itself does not support real branches, but rather uses its cheap copy operation and folder naming conventions for managing logical branches. For Teamscale to recognize a folder as a branch, it must either be a top-level folder trunk or a folder below the branches directory configured for the repository (defaults to branches). Then enable branch support and configure the URL of the SVN connector to point to the project folder, i.e., the one containing trunk and the configured branches directory. If the SVN repository in question is using the standard SVN layout, then you can simply use the branches directory option's default.
Note that Teamscale assumes all folders directly within the branches directory to be actual branches. Using further folder hierarchies to organize your branches is currently not supported. More specifically, a branch name may never contain a slash. Also, as Teamscale analyzes your history, even branches that have been deleted from the branches folder will be found and potentially be analyzed, as they are part of the recorded history. If you want to prevent this, either set a start date after the time the branch was deleted or exclude the corresponding branches using the branch exclude patterns.
Subversion Authentication Problems
In case you are running into the problem that the SVN connector validates successfully, but the SVNChangeRetriever then runs into an SVNAuthenticationException with a 403 Forbidden message, you can try to add the following to the entry JVM_EXTRA_ARGS in the file $TEAMSCALE_HOME/config/jvm.properties:
-Dcom.teamscale.enable-svn-thorough-auth-check-support=trueIf it is enabled, Teamscale will do some additional authentication checks, to find the folder closest to the repository root it can access. Because this is slower than the default, it is disabled by default.
Azure DevOps Team Foundation Version Control Credentials (formerly called Team Foundation Server (TFS))
When connecting to Azure DevOps TFVC via a repository connector, you may use either the account credentials of a domain user or a personal access token (if these are enabled in your Azure DevOps).
When configuring an account credential for an access token, enter the Azure DevOps access token in the Access Token field. The Username is optional in this case. By convention, you may use the name of the access token.
Azure DevOps Boards (formerly called Team Foundation Server Work Items)
When connecting to an Azure DevOps Server via an issue connector, please verify whether the Basic Authentication option is enabled in your IIS or not. Depending on this option, you may need to use different credentials than you used for your repository connector when connecting to the Azure DevOps to retrieve work items.
With Basic Authentication enabled:
You must connect with the credentials (username and password) of an Azure DevOps user account. Connecting with personal access tokens will not work. This may either be a domain user or an Azure DevOps user with the necessary rights to read work items.
With Basic Authentication disabled:
You must connect with a personal access token. Connecting with a user account (username + password) will not work. Put the personal access token in the Password field in the Teamscale UI. Configuring a Username in Teamscale is optional in this case. By convention, you may use the name of the TFS access token.
Artifactory Connector Options
Artifactory is a tool hosting a repository where build artifacts can be stored. Examples of such artifacts are generated code or findings generated by some external tool. It is good practice to store these in a versioned manner with a reference to the revision used to generate the given artifacts. This can be easily achieved by encoding the revision in the path of the artifact, e.g., /app/component/trunk/rev1234/artifact.zip.
Teamscale can extract such metadata from the artifact path and use it to link revisions in Artifactory to revisions in source-code repositories.
Artifactory Connector Options
To extract metadata from paths, Teamscale offers a variety of extraction options that can be configured in the Artifactory Repository Connector. These options are defined by regular expressions with exactly one capturing group. The regular expression will be applied to the complete path of the imported artifact, and the content of the capturing group will be interpreted as the data to be extracted.
If the Artifactory file layout is not yet fixed, it may prove helpful to keep ease of extraction in mind when deciding on a structure. For example, paths should include the names of the fields Teamscale should extract. This allows simpler regular expressions than when having to derive the fields from the repository layout, especially if that layout is highly diverse across different projects.
Consequently, the path /app/component/branch_trunk/rev_1234/artifact.zip is easier to parse than the path /app/component/trunk/1234/artifact.zip. However, Teamscale is flexible enough to accommodate all repository structures, even when the layout is already established.
Teamscale assumes that uploads to Artifactory are typically triggered by VCS commits. Some configuration options only make sense in this light, e.g., "Timestamp Interpretation". This option allows relating an Artifactory upload to some previous repository commit.
Artifactory Connector Configuration
| Repository | The name of the Artifactory repository which contains the relevant data |
| Name Search Pattern | The pattern (Artifactory Query Language) on the simple file name used for finding archive files. Supported wildcards are * and ?. Separate multiple patterns with comma or newline. Example: *.zip |
| Zip Exclude Pattern | Comma separated list of Ant Patterns used to exclude all archives whose full paths (path + name). Paths will be matched case-insensitively. |
| Path Search Pattern | The pattern (Artifactory Query Language) on the full path used for finding archive files. Supported wildcards are * and ?. Separate multiple patterns with comma or newline. Example: component/subcomponent/* |
| Public Context Path | The path which will be publicly used to access Artifactory. If Artifactory is accessible on the root of the server leave empty. |
| Full Scan Interval (expert option) | The interval (in seconds) in which a full scan will be performed. Depending on the Artifactory instance, this can take a long time. Might be necessary to detect deletions of older items. Can be set to -1 to disable periodic full scans. Please note that only full scans will remove any revisions which have been deleted in Artifactory from Teamscale. |
| Branch Extraction Pattern | Pattern used to extract the branch name from the full path. A regex pattern with exactly one capturing group. The group is used to find the branch name from the archive's path. Example: component/(trunk|branch)/rev |
| Timestamp Extraction Pattern | Pattern used to extract the timestamp or revision from the full path. A regex pattern with exactly one capturing group. The group is used to find the timestamp name from the archive's path. If this is empty, the creation date from Artifactory will be used. Example: /rev(\d+)/ |
| Max Change Detection Age | Changes to the history of the artifact store downloads that are older than this age (in days) will not be detected by Teamscale. |
| Timestamp Interpretation | Describes how to interpret the value from timestamp extraction. Possible values are 'date:pattern', where pattern is a Java time format descriptor, 'timestamp:seconds' and 'timestamp:millis' for unix timestamps in seconds or milliseconds, 'svn:account-name' to interpret the value as a Subversion revision, 'git:account-name' to interpret the value as a git commit hash for a repository using the 'File System' connector, and 'connector:connector-identifier' to interpret the value as a revision of a connector in the same project. In 'connector:connector-identifier', the part after the colon can be omitted, i.e., 'connector' is valid. In this case, Teamscale uses all other connectors to resolve the revision. This does not guarantee which revision is chosen, if multiple revisions with the same name are found by different connectors. |
| Prefix Extraction Pattern | Pattern used to extract an additional prefix that is placed before the name of files extracted from the ZIP files. A regex pattern with exactly one capturing group. The group is used to find the prefix from the archive's path. If this is empty, no prefix will be used. Example: variant/(var1|var2)/componentwill prepend either var1 or var2 to the path used in Teamscale |
| Ignore extraction failures (expert option) | When checked, Teamscale will try to ignore errors during timestamp extraction according to the given extraction pattern. This can be useful when many non-conforming paths are expected to be analyzed alongside the conforming paths. When this is unchecked, such errors will stop the import until they are corrected (to avoid importing inconsistent data). When this option is checked, the non-conforming paths will be skipped but all conforming paths will still be imported. |
| Delete Partitions Without New Uploads (expert option) | Whether to discard data in partitions that have not been updated in a commit in an upload to Artifactory, instead of keeping it. (off = keep data). Turning this on is useful in scenarios, where you expect to get all relevant data with every single commit (e.g. when using only fully automated tests that are run with each commit). Turning it off is useful in the inverse scenario, e.g. when using a lot of irregular manual uploads, such as when doing manual testing for test gap analysis. |
| Filter duplicate archives per revision (expert option) | When activated, Teamscale will only keep the newest archive for all archives with the same simple name (without path) that are mapped to the same revision. |
| Required ZIP path patterns (expert option) | Comma separated list of patterns for which at least one matching path of a ZIP file must be found. If this is not the case, the revision will be skipped by the connector. This can be used to skip incomplete builds. |
S3 Connector
The S3 connector enables Teamscale to connect to Amazon S3 or any object storage server with an API compatible with Amazon S3 cloud storage (e.g. MinIO). The connector then fetches the data from the object storage server, whether it's generated code or data generated by some external tool (e.g. findings, code coverage, etc.). We recommend you store the objects in archives. The path to the archive must include the revision used to generate the given artifacts, as well as the branch to which they belong, e.g., app/component/branch_name/rev_1234/artifact.zip
Teamscale can extract such metadata from the object key and use it to link revisions from the object storage server to revisions in source-code repositories.
S3 Connector Account Credentials
When connecting to Amazon S3 or any S3-compatible server via the S3 connector, you must use the account credentials of a user's service account.
Required User Permissions
The user, whose service account will be used, must have the following action permissions:
- s3:GetObject
- s3:ListBucket
Below is a sample for an IAM policy specifically created for the Teamscale technical user with only the required permissions.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::*"
]
}
]
}Account Credentials
When using http(s)-based path-style links, the used account's fields should be filled out as follows:
- URL: The base URL of the object storage server (e.g.,
http(s)://<hostname>[:port]/<bucket>[/key]). - Access Key: The service account's access key.
- Secret Key: The service account's secret key.
When using http(s)-based virtual-host-style links, the used account's fields should be filled out as follows:
- URL: The base URL of the object storage server (e.g.,
http(s)://<bucket>.<hostname>[:port][/key]). - Access Key: The service account's access key.
- Secret Key: The service account's secret key.
When using s3-style links, the used account's fields should be filled out as follows:
- URL: The base URL of the object storage server (e.g.,
s3://<bucket>[/key]). This will automatically switch to using the AWS CLI. In this configuration style, the access key and secret key are taken from the host machine. The Secret Key and Access Key in the Teamscale configuration will be ignored and can therefore be left empty.
Relationship between bucket configuration and URI
The Bucket field in the connector configuration must be filled and defines the bucket used by Teamscale. The <bucket> in the URI must match the name given in the Bucket field.
Credentials Process
An AWS credentials process may be used instead of the account's username and password. To enable this functionality, you have to set the command via the JVM property -Dcom.teamscale.s3.credentials-process-command. The command should correspond to an executable file accessible by Teamscale that will provide the credentials in the correct format when executed. You may optionally specify multiple environment variables in the admin settings under the "AWS Integration" section. They will be added to the environment of the command. For example, if the command is credentials_process, it will be executed as VAR1=VAL1 VAR2=VAL2 ... credentials_process, where VAR1, VAR2, etc., are the environment variables and their corresponding values. To avoid security risks such as potential command injection, environment variable keys and values are limited to letters and digits, i.e., a-z, A-Z, 0-9, as well as the characters '.' (dot), '-' (minus), and '_' (underscore). Finally, the option "Use Credentials Process" must be enabled in the connector for the credentials process to be used.
S3 Connector Options
To extract metadata from objects, Teamscale offers a variety of extraction options that can be configured in the S3 Repository Connector. These options are defined by regular expressions with exactly one capturing group and/or ant patterns. The regular expression will be applied to the complete key of the imported object, and the content of the capturing group will be interpreted as the data to be extracted.
If the bucket's layout is not yet fixed, it may prove helpful to keep ease of extraction in mind when deciding on a structure. For example, object keys should include the names of the fields Teamscale should extract. This allows simpler regular expressions than when having to derive the fields from the bucket's layout, especially if that layout is highly diverse across different projects.
Consequently, the path /app/component/branch_trunk/rev_1234/artifact.zip is easier to parse than the path /app/component/trunk/1234/artifact.zip. However, Teamscale is flexible enough to accommodate all bucket structures, even when the layout is already established.
Teamscale assumes that uploads to the S3 object storage server are typically triggered by VCS commits. Some configuration options only make sense in this light, e.g., "Timestamp Interpretation". This option allows relating an S3 object to some previous repository commit.
S3 Connector Configuration
| Bucket | The name of the bucket which contains the relevant objects and data. It also replaces the bucket name in the s3-style URI given in the account. |
| Key Prefixes | Strings indicating the prefixes to be used when fetching keys from the bucket. Separate multiple strings with a comma. |
| Included Key Patterns | Ant patterns describing the keys to be used for finding archive files from the bucket. Supported wildcards are * and ?. Separate multiple patterns with comma or newline. Example: *.zip |
| Excluded Key Patterns | Ant patterns describing the keys to be excluded from the bucket. Keys will be matched case-insensitively. |
| Use Credentials Process | If enabled, the configured credentials process will be used for authentication instead of the account's username and password fields. |
| Branch Extraction Pattern | Pattern used to extract the branch name from the full path. A regex pattern with exactly one capturing group. The group is used to find the branch name from the archive's path. Example: component/(trunk|branch)/rev |
| Timestamp Extraction Pattern | Pattern used to extract the timestamp or revision from the full path. A regex pattern with exactly one capturing group. The group is used to find the timestamp name from the archive's path. If this is empty, the creation date from Artifactory will be used. Example: /rev(\d+)/ |
| Max Change Detection Age | Changes to the history of the artifact store downloads that are older than this age (in days) will not be detected by Teamscale. |
| Timestamp Interpretation | Describes how to interpret the value from timestamp extraction. Possible values are 'date:pattern', where pattern is a Java time format descriptor, 'timestamp:seconds' and 'timestamp:millis' for unix timestamps in seconds or milliseconds, 'connector:connector-identifier' to interpret the value as a revision of a connector in the same project, 'svn:account-name' to interpret the value as a Subversion revision, and 'git:account-name' to interpret the value as a git commit hash for a repository using the 'File System' connector. |
| Prefix Extraction Pattern | Pattern used to extract an additional prefix that is placed before the name of files extracted from the ZIP files. A regex pattern with exactly one capturing group. The group is used to find the prefix from the archive's path. If this is empty, no prefix will be used. Example: variant/(var1|var2)/componentwill prepend either var1 or var2 to the path used in Teamscale |
| Ignore extraction failures (expert option) | When checked, Teamscale will try to ignore errors during timestamp extraction according to the given extraction pattern. This can be useful when many non-conforming paths are expected to be analyzed alongside the conforming paths. When this is unchecked, such errors will stop the import until they are corrected (to avoid importing inconsistent data). When this option is checked, the non-conforming paths will be skipped but all conforming paths will still be imported. |
| Delete Partitions Without New Uploads (expert option) | Whether to discard data in partitions that have not been updated in a commit in an upload to Artifactory, instead of keeping it. (off = keep data). Turning this on is useful in scenarios, where you expect to get all relevant data with every single commit (e.g. when using only fully automated tests that are run with each commit). Turning it off is useful in the inverse scenario, e.g. when using a lot of irregular manual uploads, such as when doing manual testing for test gap analysis. |
| Filter duplicate archives per revision (expert option) | When activated, Teamscale will only keep the newest archive for all archives with the same simple name (without path) that are mapped to the same revision. |
| Required ZIP path patterns (expert option) | Comma separated list of patterns for which at least one matching path of a ZIP file must be found. If this is not the case, the revision will be skipped by the connector. This can be used to skip incomplete builds. |
Issue Tracker Connector Options
Options for all Issue Tracker Connectors
| Import only Items Changed After | This limits which items should be imported. Example: Setting this to "1 year ago" implies that items which remained unchanged within the last year will not be imported. |
| Issue Connector Identifier | Teamscale will use this identifier to distinguish different issue connectors in the same project. (Teamscale-internal only) |
| Import Issue history since | The start timestamp of the history to retrieve. This limits the amount of history we import for each item, but does not limit which items to import. |
| Issue ID pattern in commit messages | A regular expression that matches the issue ID inside commit messages. Must contain at least one capturing group. The first capturing group of the regular expression must match the entire issue ID as it is used by the issue tracker. For example, for JIRA a valid pattern might be (JIRA-\d+) . If the regular expression can match alternate spellings that the issue tracker does not consider valid issue IDs, then these spellings must be normalized using an Issue ID transformation (see below). |
| Issue ID pattern in branch names | A regular expression that matches the issue ID inside branch names. Must contain at least one capturing group. The first capturing group of the regular expression must match the entire issue ID as it is used by the issue tracker. For example, for JIRA a valid pattern might be (jira_\d+) . If the regular expression can match alternate spellings that the issue tracker does not consider valid issue IDs, then these spellings must be normalized using an Issue ID transformation (see below). |
| Projects (except GitLab) | A comma-separated list of project names from the issue tracker. Only issues from these projects will be imported |
| Custom Fields (except GitLab) | Custom fields to be included. This is a pair list of the field's name and a boolean indicating whether the content of the field should be interpreted as a username. Example: 'release-relevant -> false, reviewer -> true'. Names must be unique within each issue. For Jira, if an issue contains multiple fields with identical names, only the first non-empty one is imported. |
| Enable Change Aggregation (expert option) | When enabled, Teamscale will aggregate multiple changes of the same author into a single change, improving analysis performance. |
| Maximum Change Aggregation Span (expert option) | The maximum interval in seconds between two subsequent changes so they can still be aggregated. This prevents changes from the same author from being aggregated when a lot of time has passed in between them. This should be shorter than the Maximum Change Aggregation Session Length. |
| Maximum Change Aggregation Session Length (expert option) | Maximum time span in seconds within which all changes by the same author may be aggregated. This ensures that you get new updates in Teamscale at least this often, even if the same author is continuously making changes in short succession. This should be longer than the Maximum Change Aggregation Span. |
| Issue ID transformation in commit messages (expert option) | A transformation expression in the form original expression -> transformed expression which can translate the issue references in commit messages to actual issue IDs in the issue tracker. For example, JIRA-(\d+) -> MY_PROJECT_KEY-$1 (using the Issue ID pattern in commit messages (JIRA-\d+)).Important: original expression is applied to matches of the capturing groups in the Issue ID pattern in commit messages option (not the entire commit message).In transformed expression, capturing groups from original expression can be referenced by $1, $2, ... |
| Issue id transformation in branch names (expert option) | A transformation expression in the form original expression -> transformed expression which can translate the issue references in branch names to actual issue IDs in the issue tracker. For example, jira_(\d+) -> MY_PROJECT_KEY-$1 (using the Issue ID pattern in branch names (jira_\d+)).Important: original expression is applied to matches of the capturing groups in the Issue ID pattern in branch names option (not the entire commit message).In transformed expression, capturing groups from original expression can be referenced by $1, $2, ... |
| Hide resolved findings in issue badges (expert option) | If enabled, all resolved findings in the badges for a single issue will be hidden. |
Jazz-specific Issue Tracker Connector Options
| Item types | The types of work items to retrieve. Leave empty for all item types. |
| Field filter expression (expert option) | A pattern to filter work items based on their fields. This is sent to the Reportable REST API and will be concatenated with a logical AND to any existing filters. |
(App based) GitHub-specific Issue Tracker Connector Options
There is no project option for this issue tracker, since this connector is directly tied to a specific repository.
| Repository Path | The path to the repository, e.g. 'cqse/teamscale-python-client'. |
| GitHub Server URL | The URL the GitHub instance is reachable at. The GitHub server URL selection dropdown menu is shown below. A How-To to connect GitHub with Teamscale can be found here |
Jira-specific Issue Tracker Connector Options
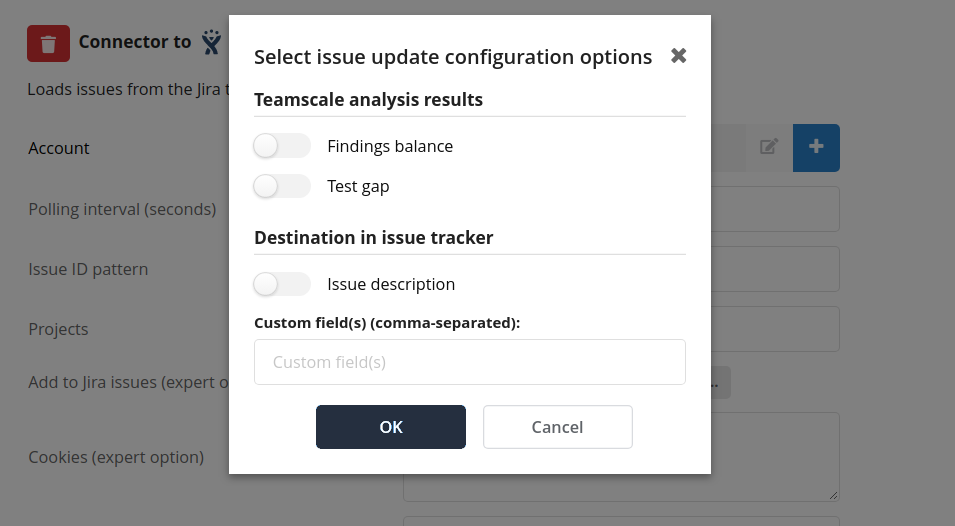
| Add to Jira issues | Allows to configure active (push) update of Jira issues with analysis results from Teamscale. The Jira issue update configuration menu is shown below. An example of a Jira issue field enhanced with Teamscale-generated data can be seen in this guide. |
| Issue types | The issue types that will be imported from Jira, e.g., Bug, Story. Leave empty to import all issue types. |
| Remove deleted issues (expert option) | Whether issues deleted in Jira should also be deleted in Teamscale. If enabled, the first poll per day will also check for issues deleted in Jira and remove them from Teamscale. In order to detect deleted issues, every issue has to be fetched from the Jira server. This can be a rather expensive operation, even when no issues are deleted. |
| Cookies (expert option) | Cookies (written as (<domain>:)?<name>=<value>) to be sent along with the request. |
TFS Worker Item-specific Issue Tracker Connector Options
| Areas | A list of full area paths to extract work items from. |
| Include Sub-Areas | If checked, issues from sub-areas are retrieved as well, otherwise just issues exactly matching one of the area paths are retrieved. |
| Item Types | The types of work items to retrieve as a comma-separated list. Leave empty for all item types. |
| Closed states | If a work item is in one of these states it is considered closed. |
| Retrieve history | If checked, the full history of a work item is retrieved. This can lead to high load on the TFS-Server. |
| Retrieve parent links | If checked, any parent relationship will be retrieved. This can lead to more load on the TFS-Server. |
RTC/Jazz-specific Issue Tracker Connector Options
| Field filter expression | An expression used to filter issues that should be imported. Must conform to RTC/Jazz’s Reportable REST API specification. |
| Item types | Allows to select the work item types to import from RTC/Jazz. Leave empty for all item types. |
GitLab Issue Tracker Connector Options
| Project | The global (numeric) project ID or the complete path (<namespace>/<projectPath>) of the project. |
| Labels | Comma-separated list of labels. Only issues with any of these labels are imported. Leave empty to import all issues. |
Commit Message-based Issue Tracker Connector Options
| Issue subject pattern in commit messages | Regular expression that extracts an issue subject from the commits (optional). |
Jira Server Issue Update Option Details
The Add to Jira issues (expert option) allows to configure the type of Teamscale analysis results appended to Jira issues as well as the destination field(s) of Teamscale-generated data in matched issues. The following analysis results can be appended to matched Jira issues:
Findings balance suboption allows to update Jira issue(s) with finding badges that contain the counts of added/removed/changed code findings introduced by the respective issue(s).
Test gap suboption allows to update Jira issue(s) with the test gap ratio of the respective issue(s). The test gap ratio also includes changes from child issues in case the Jira issue acts as a parent for other issues.
Both suboptions are linked to the Issue perspective where all issue-related information can be viewed.
Additionally, it is possible to configure the field(s) of Jira issues that Teamscale-generated data should be appended to:
Issue description suboption allows to append Teamscale-generated data to issue description.
Custom field(s) suboption allows to write Teamscale-generated data to specified custom fields. This will overwrite any existing data in the field. The custom fields have to be created by Jira Administrator and be of Text Field (multi-line) type.
Requirements Management Tool Connector Options
Options for all Requirements Management Tool Connectors
| Projects / Project ID | Name of the project(s) in the requirements management tool to import spec items from. |
| Requirements Connector Identifier | Teamscale will use this identifier to distinguish different requirements management tool connectors in the same project. (Teamscale-internal only) |
| Specification item ID pattern | A regular expression that matches the spec item ID inside source code entity comments. Must contain at least one capturing group. The first capturing group of the regular expression must match the entire spec item ID as it is used by the requirements management tool. For example, for Polarion a valid pattern might be (DP-\d+). |
| Enable Spec Item analysis | Whether Teamscale should analyze the imported Spec Items. Please note that the checks to execute have to be configured separately in the selected analysis profile. |
| Spec Item types to analyse | Comma separated list of Spec Item types (or type abbreviations) to analyze. If empty, all imported Spec Items will be analyzed. |
| Verifies Relationships | List of 'verifies' relations between different Spec Item types. This is helpful if some spec items represent tests. Example: (*) --[tests]-> (*) |
| Custom fields (expert option) | Allows to specify the custom fields to import with the spec items. Custom fields have to be selected separately, as they are non-standard fields that are configured for each project individually. |
Jira-specific Requirements Management Tool Connector Options
| Issue types | The mapping from the issue types that will be imported from Jira to the type abbreviations used in the UI. Typical Examples:
|
| Projects | The projects (or products) in the Jira tracker that specification items are extracted from. It is possible to specify the project key or the project name. |
Polarion-specific Requirements Management Tool Connector Options
| Specification space name | Allows to select the space to import the documents from. |
| Document (module) ID(s) | Allows to select the documents to import. The documents can be specified as a comma-separated list of document IDs and/or document ID regular expressions. |
| Included work item types (expert option) | Allows to select the work item types to import from Polarion (requirements, test cases, etc.) and their respective type abbreviations for use in Teamscale UI. |
| Included work item link roles (expert option) | Allows to select the work item links to import (duplicates, is implemented by, etc.). |
| Remove deleted items (expert option) | Whether specification items deleted in Polarion should also be deleted in Teamscale. If enabled, the first poll per day will also check for specification items deleted in Polarion and removes them from Teamscale. In order to detect deleted specification items, every specification item id has to be fetched from the Polarion server. This can be a rather expensive operation, even when no specification items are deleted. |
| Work item link pattern (expert option) | Pattern to extract work item links from the HTML of a document. This is required, in order to correctly detect items, that are in the 'Recycle Bin' of a document. The Pattern must contain a group called workItemId, which matches the id of the referenced work item. |
RTC/Jazz-specific Requirements Management Tool Connector Options
| Projects | The projects (or products) in the RTC tracker that specification items are extracted from. |
| Item types | Allows to select the work item types to import from RTC/Jazz and their respective type abbreviations for use in the Teamscale UI. |
| Field filter expression (expert option) | An expression used to filter work items that should be imported. Must conform to RTC/Jazz’s Reportable REST API specification. |
| Custom Fields | Custom fields to be included. This is a pair list of the field's name or id and a boolean indicating whether the field is user defined (true) or a standard field in RTC. For standard fields, the id must be specified; for user defined fields, the display name. Typical examples:
|
| Included work item link roles (expert option) | Links between work items to be included. |
Azure-Devops-specific Requirements Management Tool Connector Options
| Areas | The areas to extract work items from (full area paths). |
| Include Sub-Areas | If checked, issues from sub-areas are retrieved as well, otherwise just issues exactly matching one of the area paths are retrieved. |
| Item Types | The types of work items to retrieve. Leave empty for all item types. Specify type abbreviations after the arrow symbol. |
| Closed states | If a work item is in one of these states it is considered closed. |
| Retrieve history | Whether the full history of a work item should be retrieved. This can lead to high load on the TFS-Server. |
| Included work item link roles (expert option) | Determines how often Teamscale should clean up work items that were deleted in Azure DevOps or moved out of the configured Area(s). Depending on the number of work items, such a cleanup operation can lead to more load on the Azure DevOps server. Examples:
|
| Perform work item cleanup on every Nth poll | If checked, issues from sub-areas are retrieved as well, otherwise just issues exactly matching one of the area paths are retrieved. |
| Projects | The projects (or products) in the requirements management tool that spec items are extracted from. |
| Custom Fields | Custom fields to be included. This is a pair list of option name and a boolean indicating whether the content of the field should be interpreted as a username. Typical examples:
|
| Item types representing test items (expert option) | Item types (or the abbreviation) that represent test items, which Teamscale should parse and treat as tests. |
Codebeamer-specific Requirements Management Tool Connector Options
| Project Names | Comma separated list of the names of projects to import items from. |
| Tracker Names | Comma separated list of the names of trackers to import items from. |
| Tracker to Types Mapping | Defines a mapping from the tracker name to a certain type. This overrides the type of items retrieved from the tracker. Examples:
|
| Tracker Types | The types of trackers to retrieve items from. Leave empty for all tracker types. Specify type abbreviations after the arrow symbol. |
| Tracker Item Categories | The categories of tracker items to retrieve. Leave empty for all tracker item categories. |
| CodeBeamer Server Time Zone | The time zone of the Codebeamer server. Unfortunately, Codebeamer only uses local date-time values when transmitting work items, which could result in incorrect timestamps within Teamscale. If not set, Teamscale assumes the Codebeamer server uses the same time zone as Teamscale. Typical Examples:
|
| Item types representing test items (expert option) | Item types (or the abbreviation) that represent test items, which Teamscale should parse and treat as tests. |
| Remove deleted items (expert option) | Whether tracker items deleted in Codebeamer should also be deleted in Teamscale. If enabled, the first poll per day will also check for tracker items deleted in Codebeamer and remove them from Teamscale. In order to detect deleted tracker items, every tracker item has to be fetched from the Codebeamer server. This can be a rather expensive operation, even when no tracker items are deleted. |
GitLab Issues as Requirement Management Tool
| Project | The global (numeric) project ID or the complete path (<namespace>/<projectPath>) of the project. |
| Labels | Comma-separated list of labels. Only issues with any of these labels are imported. Leave empty to import all issues. |