How to Record Test Coverage for JavaScript Applications in the Browser
This how-to describes how test coverage information can be recorded for a JavaScript application running in a web browser (Firefox, Chrome, Electron, ...) using the Teamscale JavaScript Profiler.
The outlined approach is particularly suited for scenarios where the system under test is deployed to a server and tests are running against that server. This might either happen via manual tests or also by automated UI tests.
It is also suited for legacy systems that use a testing approach with no explicit means to collect coverage information.
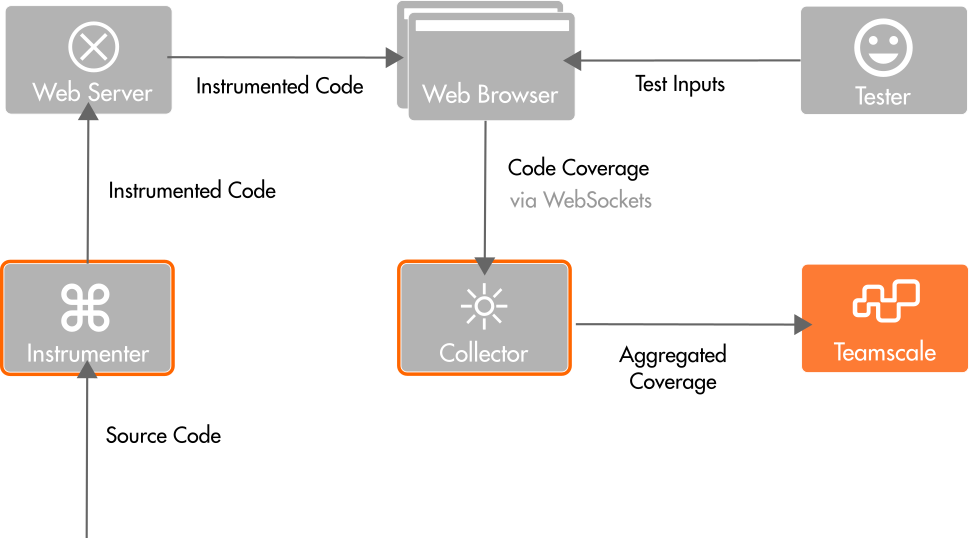
The above figure illustrates the overall process:
- compile (or transpile) your application into the JavaScript code to be executed in the Web browser
- instrument the compiled source code using our JavaScript Instrumenter
- start the Coverage Collector to receive coverage information from browsers that run your application
- start your instrumented application in the web browser and begin producing test coverage
- if configured, the collector will automatically upload test coverage to Teamscale
For Node.js applications, please follow our Node.js coverage How-To. For tests with a less complicated setup, for example, JavaScript unit tests, there are often simpler solutions, which are discussed under alternatives.
Prerequisites
To use the Teamscale JavaScript Profiler, a number of prerequisites have to be in place.
The instrumented code must be executed in a (possibly headless) browser environment that supports at least ECMAScript 2015. Furthermore, we require that a DOM and WebSockets are available in that execution environment. In other words, the approach supports Edge >= v79, Firefox >= v54, Chrome >= v51, and Safari >= v10. Instrumented applications will fail in Node.js.
To run the components of the profiler, we recommend using the latest Node.js LTS version, at least, version 14 is needed.
Source Maps
The code which is executed in the browser often does not correspond to the code written by the developers. It can be the result of several transformation steps, for example, compilation (transpilation) from other languages, source code minimization, or bundling.
The presence of source map files in the code of the test subject ensures that the tested code can be mapped back to the original. Depending on your build pipeline, a different approach must be chosen to add the source maps to the test subject's code bundle.
In the following we provide pointers to relevant configuration options for some of the popular tools used in the context of JavaScript applications:
// tsconfig.json
{ compilerOptions: { sourceMap: true, inlineSources: true, ... }, ... }See the Typescript documentation for more details and options.
Content Security Policy
To use the profiler, the application's Cross-Origin Resource Sharing (CORS) has to be adjusted. The instrumented application sends coverage information via WebSockets to a collecting server. That is, communication via WebSockets must be allowed. Whether this is allowed is determined by the Content-Security-Policy attribute. This attribute is either part of the HTTP header sent by the Web server delivering the Web application, or by a corresponding HTML entry. If the collecting server is running on the same machine as the browser, then communicating with localhost must be allowed by adding ws://localhost:* for connect-src, blob, and worker-src to the Content-Security-Policy header.
The following snippet shows the content security policy that has to be added for allowing accessing the collector at host <collectorHost> on port <port>:
connect-src 'self' ws://<collectorHost>:<port>;
script-src 'self' blob: ws://<collectorHost>:<port>;
worker-src 'self' blob: ws://<collectorHost>:<port>;By not specifying a content security policy, everything would be allowed. This can also be specified explicitly, for testing environments:
default-src * data: blob: filesystem: about: ws: wss: 'unsafe-inline' 'unsafe-eval' 'unsafe-dynamic'; script-src * data: blob: 'unsafe-inline' 'unsafe-eval'; connect-src * data: blob: 'unsafe-inline'; img-src * data: blob: 'unsafe-inline'; frame-src * data: blob: ; style-src * data: blob: 'unsafe-inline'; font-src * data: blob: 'unsafe-inline';The place to configure the content security policy depends on the backend framework that serves the frontend code. See, for example, the Spring documentation on that topic.
Configuring Coverage Collection in Teamscale
There are various ways and parameters to configure how coverage is collected using the Teamscale JavaScript Profiler. We recommend defining a coverage profiling configuration in Teamscale and referencing that via --config-id when instrumenting the application to test. This can be done in Coverage Profilers View in Teamscale under Project Configuration > Coverage Profilers. For this HowTo, we define an example configuration with the ID rc-testing-web-frontend, with the following options set:
teamscalePartition=RC Testing
teamscaleProject=angular-hero-app
dumpAfterMins=120Configuration Refresh
The collector configurations are refresh from Teamscale once a minute, or if requested explicitly via the /refresh end point of the control API.
Instrumentation
Before we can produce any coverage from a JavaScript application, this application has to be instrumented. For this we use the Teamscale JavaScript Instrumenter package.
Installing and Running
The instrumenter is available as a Node.js package with the name @teamscale/javascript-instrumenter.
We recommend npx or pnpm exec to execute the instrumenter. For example, the following command is used to instrument an example app.
npx @teamscale/javascript-instrumenter \
--input ./dist/ \
--collector localhost:54678 \
--config-id rc-testing-web-frontend \
--commit 4f845c120051b0fbf3f61bb9edb747f114b39433 \
--in-place \
--include-origin 'src/app/**/*'Here is a short breakdown of that command:
- It instructs the Instrumenter to instrument the code compiled/transpiled/minified code in the target folder
./dist/. - It expects that the collector (
--collector) will be running atlocalhost:54678. - The collector configuration with the ID
rc-testing-web-frontendshall be received from Teamscale to the collector's coverage dump behavior. - The collected coverage shall be assigned to the commit with the Git commit hash
4f845c120051b0fbf3f61bb9edb747f114b39433. - The instrumentation is done in-place (
--in-place), that is, existing files are replaced by their instrumented counterparts. - The relevant source files (
--include-origin) that should be matched against are located insrc/app/**/*.
For more information on the defined and available option parameters, have a look at our reference page.
Now there should be an instrumented version of your application in the dist folder.
Coverage Collector
Now that the code has been instrumented to produce and send coverage information, we describe how to set up the coverage collector.
Installing and Running
The collector is available as a Node.js package with the name @teamscale/coverage-collector and as docker image.
Running using NPX
The collector can be installed and started using the npx command. The following command starts the collector on the default port 54678. The coverage will be dumped into the default folder ./coverage:
npx @teamscale/coverage-collectorRunning as Node Script
The package @teamscale/coverage-collector can be added as a development dependency to the package.json file. For example, by running npm install -D @teamscale/coverage-collector (or pnpm add -D @teamscale/coverage-collector).
After installing the package it should be registered in the package.json and be available locally for being executed. Please check the NPM package registry for the latest version of the package regularly.
Now we have to start the collector before testing is done and have to stop it after this process has been finished. For this, we propose to use the pm2 package. The usage of pm2 is illustrated by following scripts in a package.json:
"scripts": {
"collector": "coverage-collector",
"pretest": "npx pm2 delete CC; npx pm2 start npm --name CC -- run collector",
"test": "jest",
"posttest": "npx pm2 delete CC"
},Please see the npmjs documentation for details on the pre and post scripts used in the above example.
That's it! Now the collector will receive the coverage information from the running application and generate the coverage reports.
Running inside Docker Image
The docker image is available at dockerhub.To execute it run the image in your preferred configuration, for example using docker run:
docker pull cqse/teamscale-coverage-collector:latest
docker run teamscale-coverage-collector-teamscale-coverage-collector:latest <args>The options available to configure the collector can simply be passed to the image as arguments.
Configuration
To further configure the collector, have a look at the options in our Reference page.
Uploading Coverage for Inspection
When the code to be tested was instrumented and the collector is running, code coverage will be produced and collected when running the code.
You can use the configuration you created in Teamscale's UI under Project Configuration > Coverage Profilers to configure the collector to upload coverage directly to Teamscale. See the list available collector options. Alternatively, the default setting of the collector is to write coverage files to disk in the Teamscale Simple Coverage Format.
Whenever a testing process has been finished (for example, in the build pipeline), the coverage can be provided to Teamscale for being used, for example, for a Test Gap Analysis. This can be done by using the Teamscale Upload Tool or by using the REST API directly. More details can be found in the corresponding documentation.
The collector can also be configured to send the collected coverage directly to a Teamscale server. The upload is enabled by setting the URL of the Teamscale server using parameter --teamcale-server-url along with Teamcale credentials and parameters that define the target project and commit of the upload.
Alternatives
The above approach works for all JavaScript applications that are run in the browser.
Some automated E2E testing frameworks, such as, Cypress, can dump coverage information directly.
For unit tests, established tools such as Jest can produce coverage reports.